

因vue是spa单页面应用,对seo不友好,所以针对该问题整合了目前网上提到的解决方案以供参考
了解SEO
搜索引擎优化(Search engine optimization,简称seo),指为了提升网页在搜索引擎自然搜索结果中(非商业性推广结果)的收录数量以及排序位置而做的优化行为,是为了从搜索引擎中获得更多的免费流量,以及更好的展现形象。
seo对vue单页面不友好的原因
- 爬虫在爬取的过程中,不会去执行js,所以隐藏在js中的跳转也不会获取到
- vue通过js控制路由然后渲染出对应的页面,而搜索引擎蜘蛛是不会去执行页面的js的,导致搜索引擎蜘蛛只能收录index.html一个页面,在百度中就搜索不到相关的子页面的内容。
- 我们加载页面的时候,浏览器的渲染包含:html的解析、dom树的构建、cssom构建、javascript解析、布局、绘制,当解析到javascript的时候才回去触发vue的渲染,然后元素挂载到id为app的div上,这个时候我们才能看到我们页面的内容,所以即使vue渲染机制很快我们仍然能够看到一段时间的白屏情况,用户体验不好
常见解决方案
- 1.SSR服务器渲染;
- 2.静态化;
- 3.预渲染prerender-spa-plugin;
- 4.使用Phantomjs针对爬虫做处理。
1.SSR服务器渲染
关于服务器渲染:Vue官网介绍,对Vue版本有要求,对服务器也有一定要求,需要支持nodejs环境。
使用SSR权衡之处:
- 开发条件所限,浏览器特定的代码,只能在某些生命周期钩子函数 (lifecycle hook) 中使用;一些外部扩展库 (external library) 可能需要特殊处理,才能在服务器渲染应用程序中运行;
- 环境和部署要求更高,需要Node.js server 运行环境;
- 高流量的情况下,请准备相应的服务器负载,并明智地采用缓存策略。
优势:
- 更好的 SEO,由于搜索引擎爬虫抓取工具可以直接查看完全渲染的页面;
- 更快的内容到达时间 (time-to-content),特别是对于缓慢的网络情况或运行缓慢的设备。
不足:(开发中遇到的坑)
1.一套代码两套执行环境,会引起各种问题,比如服务端没有window、document对象,处理方式是增加判断,如果是客户端才执行:
if(process.browser){
console.log(window);
}
引用npm包,带有dom操作的,例如:wowjs,不能用import的方式,改用:
if (process.browser) {
var { WOW } = require('wowjs');
require('wowjs/css/libs/animate.css');
}
2.Nuxt asyncData方法,初始化页面前先得到数据,但仅限于页面组件调用:
// 并发加载多个接口:
async asyncData ({ app, query }) {
let [resA, resB, resC] = await Promise.all([
app.$axios.get('/api/a'),
app.$axios.get('/api/b'),
app.$axios.get('/api/c'),
])
return {
dataA: resA.data,
dataB: resB.data,
dataC: resC.data,
}
}
在asyncData中获取参数:
1.获取动态路由参数,如:
/list/:id' ==> '/list/123
接收:
async asyncData ({ app, query }) {
console.log(app.context.params.id) //123
}
2.获取url?获取参数,如:
/list?id=123
接收:
async asyncData ({ app, query }) {
console.log(query.id) //123
}
3.如果你使用v-if语法,部署到线上大概也会遇到这个错误:
Error while initializing app DOMException: Failed to execute 'appendChild' on 'Node': This node type does not support this method.
at Object.We [as appendChild]
根据github nuxt上的issue第1552条提示,要将v-if改为v-show语法。
2.静态化
静态化是Nuxt.js打包的另一种方式,算是 Nuxt.js 的一个创新点,页面加载速度很快。 在 Nuxt.js 执行 generate 静态化打包时,动态路由会被忽略。
-| pages/
---| index.vue
---| users/
-----| _id.vue
需要动态路由先生成静态页面,你需要指定动态路由参数的值,并配置到 routes 数组中去。
// nuxt.config.js
module.exports = {
generate: {
routes: [
'/users/1',
'/users/2',
'/users/3'
]
}
}
运行打包,即可看见打包出来的页面。 但是如果路由动态参数的值是动态的而不是固定的,应该怎么做呢?
- 使用一个返回 Promise 对象类型 的 函数;
- 使用一个回调是 callback(err, params) 的 函数。
// nuxt.config.js
import axios from 'axios'
export default {
generate: {
routes: function () {
return axios.get('https://my-api/users')
.then((res) => {
return res.data.map((user) => {
return {
route: '/users/' + user.id,
payload: user
}
})
})
}
}
}
现在我们可以从/users/_id.vue访问的payload,如下所示:
async asyncData ({ params, error, payload }) {
if (payload) return { user: payload }
else return { user: await backend.fetchUser(params.id) }
}
如果你的动态路由的参数很多,例如商品详情,可能高达几千几万个。需要一个接口返回所有id,然后打包时遍历id,打包到本地,如果某个商品修改了或者下架了,又要重新打包,数量多的情况下打包也是非常慢的,非常不现实。 优势:
- 纯静态文件,访问速度超快;
- 对比SSR,不涉及到服务器负载方面问题;
- 静态网页不宜遭到黑客攻击,安全性更高。
不足:
- 如果动态路由参数多的话不适用。
3.预渲染prerender-spa-plugin
如果你只是用来改善少数营销页面(例如 /, /about, /contact 等)的 SEO,那么你可能需要预渲染。无需使用 web 服务器实时动态编译 HTML,而是使用预渲染方式,在构建时 (build time) 简单地生成针对特定路由的静态 HTML 文件。优点是设置预渲染更简单,并可以将你的前端作为一个完全静态的站点。
$ cnpm install prerender-spa-plugin --save
vue cli 3 vue.config.js配置:
const PrerenderSPAPlugin = require('prerender-spa-plugin');
const Renderer = PrerenderSPAPlugin.PuppeteerRenderer;
const path = require('path');
module.exports = {
configureWebpack: config => {
if (process.env.NODE_ENV !== 'production') return;
return {
plugins: [
new PrerenderSPAPlugin({
// 生成文件的路径,也可以与webpakc打包的一致。
// 下面这句话非常重要!!!
// 这个目录只能有一级,如果目录层次大于一级,在生成的时候不会有任何错误提示,在预渲染的时候只会卡着不动。
staticDir: path.join(__dirname,'dist'),
// 对应自己的路由文件,比如a有参数,就需要写成 /a/param1。
routes: ['/', '/product','/about'],
// 这个很重要,如果没有配置这段,也不会进行预编译
renderer: new Renderer({
inject: {
foo: 'bar'
},
headless: false,
// 在 main.js 中 document.dispatchEvent(new Event('render-event')),两者的事件名称要对应上。
renderAfterDocumentEvent: 'render-event'
})
}),
],
};
}
}
在main.js中添加:
new Vue({
router,
render: h => h(App),
mounted () {
document.dispatchEvent(new Event('render-event'))
}
}).$mount('#app')
注意:router中必须设置 mode: “history”。
打包出来可以看见文件,打包出文件夹/index.html,例如:about => about/index.html,里面有html内容。
优势:
- 改动小,引入个插件就完事;
不足:
- 无法使用动态路由;
- 只适用少量页面的项目,页面多达几百个的情况下,打包会很很很慢;
4.使用Phantomjs针对爬虫做处理
Phantomjs是一个基于webkit内核的无头浏览器,即没有UI界面,即它就是一个浏览器,只是其内的点击、翻页等人为相关操作需要程序设计实现。 虽然“PhantomJS宣布终止开发”,但是已经满足对Vue的SEO处理。 这种解决方案其实是一种旁路机制,原理就是通过Nginx配置,判断访问的来源UA是否是爬虫访问,如果是则将搜索引擎的爬虫请求转发到一个node server,再通过PhantomJS来解析完整的HTML,返回给爬虫。
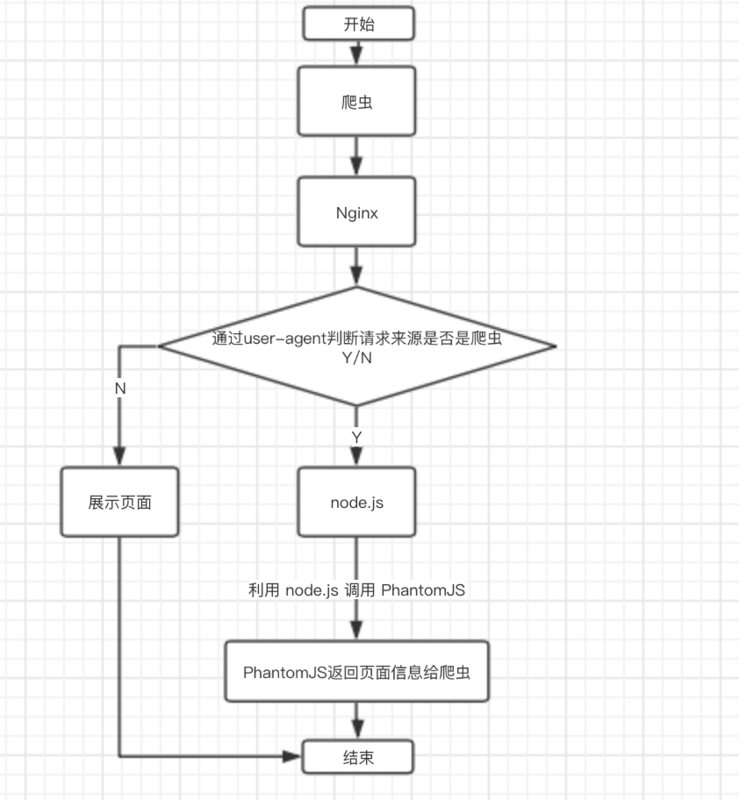
具体代码戳这里:vue-seo-phantomjs。 要安装全局phantomjs,局部express,测试:
$ phantomjs spider.js 'https://www.baidu.com'
如果见到在命令行里出现了一推html,那恭喜你,你已经征服PhantomJS啦。 启动之后或者用postman在请求头增加User-Agent值为Baiduspider,效果一样的。
部署上线 线上要安装node、pm2、phantomjs,nginx相关配置:
upstream spider_server {
server localhost:3000;
}
server {
listen 80;
server_name example.com;
location / {
proxy_set_header Host $host:$proxy_port;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
if ($http_user_agent ~* "Baiduspider|twitterbot|facebookexternalhit|rogerbot|linkedinbot|embedly|quora link preview|showyoubot|outbrain|pinterest|slackbot|vkShare|W3C_Validator|bingbot|Sosospider|Sogou Pic Spider|Googlebot|360Spider") {
proxy_pass http://spider_server;
}
}
}
优势:
- 完全不用改动项目代码,按原本的SPA开发即可,对比开发SSR成本小不要太多;
- 对已用SPA开发完成的项目,这是不二之选。
不足:
- 部署需要node服务器支持;
- 爬虫访问比网页访问要慢一些,因为定时要定时资源加载完成才返回给爬虫;
- 如果被恶意模拟百度爬虫大量循环爬取,会造成服务器负载方面问题,解决方法是判断访问的IP,是否是百度官方爬虫的IP。
引用来源点击这里,原作者的内容比较详细,里面多补充一些其它必要知识